Overview
As a developer, I have mostly used and designed my application utilizing SQL databases like PostgreSQL and MySQL. I have a bit of familiarity using MongoDb, However it has been a while and most of those concepts have been forgotten due to my lack of use. Recently, I wanted to develop a web application focused around collaboration of multiple parties over the web. The project would be based on text based data. However, real time updates would be required similar to how you are able to work with multiple people on the same google doc and see what each individual is typing and even where their cursor is within the document. Since these changes need to be persisted there will be a large number of write and read operations. While SQL databases are a good option for ready heavy applications with structured data, they fall behind to their counterparts when it comes to write heavy applications that require real time updates. Since I needed to host my application on the cloud I decided to choose AWS DynamoDb for this purpose. This is my documentation on the basic concepts of Dynamo Db that I learned.
Important Considerations
- Regional Resilience
- Consistent Performance with data
- Data spread across multiple servers
- Regional Resilience due to how data is spread
- HTTP Connections vs Generic TCP Connections in Relational Dbs (Postgres: 100 persistent connections)
- No performance degradation as data increases
- IAM authentication vs username and password model (ideal for serverless architecture)
- IAAC Friendly using terraform or cloudformation
- Different pricing model (Pay for read and write cap units vs CPU, RAM provisioning)
- 1 RCU = 1 consisted read per sec / 2 eventually consistent reads per sec upto 4Kb in size
- 1 WCU = write a single item per sec
- You can tweak RCU and WCU separately Dynamic scaling based on workload
- Ideal for serverless architecture (No worries about VPC due to HTTP connections and IAM auth)
Common Misconceptions
- Dynamo Db is only a key value store It is so much more. Can handle more complex Db operations
- Dynamo Db does not scale Only if you model it wrong and use scans in access patterns
- Dynamo Db should only be used for scale Easy provisioning, pay per usage disagrees
- Don't use it your data model will changes Modelling is based on how data is queried vs objects in a relational Db However, you can change it and most changes tend to be additive
- You don't need a schema. It is true schema is not enforced on a Db level However is a quick pathway into madness as it needs to be enforced on an app level
- All NoSQL databases are the same. (Nope! It just means they don't use SQL for querying like relational Dbs. Multiple NoSQL Db types such as key value like dynamoDb, column based like mongoDb, graph like Neo4j)
Key value / Column based
Dynamo Db can be used in 2 ways and thus data in dynamo Db can be modeled in 2 ways:
- Key value : For simpler designs
- Wide column : Value in hash table is a B-tree
Key concepts
- Table
- Items
- Attributes
- Primary Key
- Secondary Index
Table
- Container for items like a relational Db
- Unlike a relational Db can have multiple entities in the same table (Customers, Orders, Etc:)
- No specified schema for the items contained within the table
- Try to avoid the Join operation which is expensive as Db scales
Item
- A single record in a table
- Similar to a row in a relational Db or document in MongoDb
Attributes
- Db items are a collection of attributes
- For example a "User" item can have an attribute of "name" with value "Chanaka"
- Attributes are similar to column in a relational Db
- However, unlike a relational Db they are not required
- Each attribute has a certain type
- 10 types in total grouped into 3 categories
- Scalars: Single value. 5 types (string, integer, boolean, binary, null)
- Complex: Groupings. 2 types (Maps, Arrays)
- Sets: Group of unique values. 3 types (string set, integer set, binary set)
- Can perform different operations based on type of attribute
- Can update numbers by adding or subtracting or checking existence of a value in a set
Primary Key
- Similar to the key in a hashmap
- Can be single value or composite consisting of a combination of 2 values
- Simple primary key: Singular value and contains only a Partition Key (also called Hash Key)
- Composite primary key: Contains Partition key & Sort key (also called Range Key)
- For fetching a singular item & one to one operations: Simple primary key
- For fetching many items at a time: Composite primary key
- You can fetch multiple items with the same partition key and sort/filter them using the sort key
- Writing an element without a primary key will not work
- Wiring an element with a primary key that exists will cause existing item to be overwritten
Secondary Indexes
- Limited data access patterns if we can only use the primary key
- Secondary Indexes provide an alternative
- Secondary Indexes are created by specifying primary key
- Queries can then be made against secondary index
- AWS copies items from main table to secondary index in new form
- 2 types of secondary indexes: Global & Local
- Local: Same partition key & different sort key
- Global: Different partition key & different sort key (can choose any attribute as partition and sort key)
- Local does not require additional throughput (RCU & WCU) as it the same core table
- Global provides more flexibility but requires a different table and thus more throughput
- Global only gives you eventual consistency vs strong consistency
- Data might be slightly different across nodes as they are replicated
- Since data is written asynchronously data in secondary index might be outdated compared to primary table
- Local gives you option to opt for strong consistent reads at the cost of more RCU
Item collections
- A group of items in a table with the same partition key is called a collection
- Important for partitioning: Dynamo Db spreads data across multiple nodes but keeps data with same partition key in one node
- Important for data modelling: Since you can gather multiple items with same partition key quickly important for data access patterns
Dynamo Db Streams
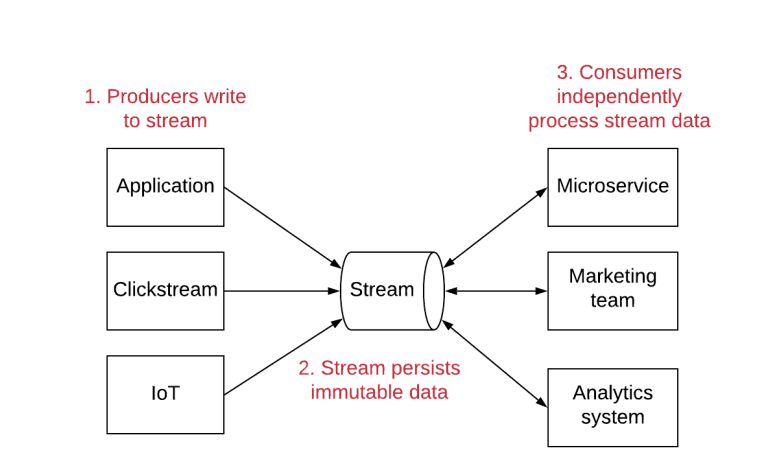
- Streams are an immutable set of records that can be read by multiple independent consumers
- Consumer Producer architecture similar to Kafka
- Track the changes across a item over time
- The changed item can be sent to multiple consumers which can all implement their own logic
TTL (Time to Live)
- Mechanism for storing temporary or short lived data within Dynamo Db
- TTL is specified as an attribute on items that you want to mark for deletion
- Attribute should be stored as an UNIX timestamp indicating when an item should expire
- TTL can be omitted from items that you want to persist permanently
- AWS makes scans of your table to check for this attribute to see if an item needs to be deleted
- AWS guarantees item will be deleted within 48 hrs from specified TTL time
- Therefore, possible to have items past their TTL so you should always check if item is expired programmatically
Partitions
- Data in Dynamo Db is sharded across multiple servers
- The partition key determines on which server your data is stored
- A hash function is applied to the partition key and the result determines the server
- Uses adaptive capacity: Throughput is spread around your table to items that need it
- Makes it easy to scale horizontally by adding multiple server nodes
Consistency
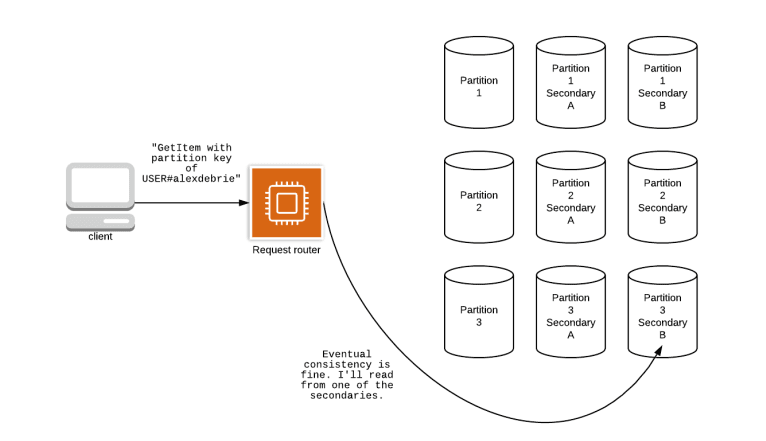
- Whether a read operation has received all the write operations till now
- Path of an incoming write operation to Dynamo Db:
- Intercepted by request router -> check permissions -> hash partition key -> forward to partition -> write to primary node -> write to secondary node -> send client confirmation -> async write to third node
- There is one primary node that contains a consistent copy of the data
- The two other secondary nodes provide fault tolerance to avoid a loss of data if the primary node goes down
- Secondary nodes also serve read requests
- Since write are replicated asynchronously from primary to other nodes it is possible to get inconsistent data if read is done on a secondary node
- Default read operations are eventually consistent
- However, can opt in for strong consistent reads by passing "Consistent read=True" in the API call
- Consistent reads consume twice as much RCU as Eventually consistent reads
- A secondary index will only allow Eventually consistent reads due to how data needs to be replicated
Limitations
- Items size limits: A single item < 400 Kb
- Query and scan limits: Result set < 1 Mb (This is before any filter operations are applied)
- If result set is larger you will need to paginate using multiple requests
- WCU on a single partition < 3000
- RCU on a single partition < 1000
- If you have a local secondary idx: item collection < 10Gb
- Writes will be rejected once you run out of space
- Global secondary idx does not have this limitation
- Storage will get split across multiple partitions under the hood